We’re working through binomial and geometric distributions this week in AP Stats, and there are many, many seeds which get planted in this chapter which we hope will yield bumper crops down the road. In particular, normal estimates of a binomial distribution – which later become conditions in hypothesis testing – are valuable to think about now and tuck firmly into our toolkit. This year, a Desmos exploration provided rich discussion and hopefully helped students make sense of these “rules of thumb”.
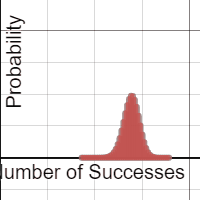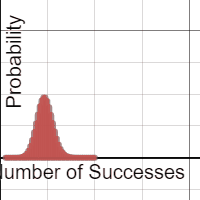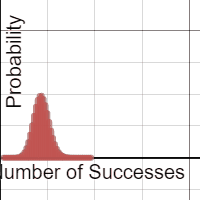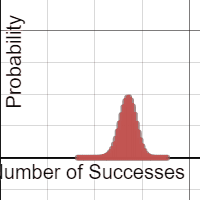 Each group was equipped with a netbook, and some students chose to use their phones. A Desmos binomial distribution explorer I had pre-made was linked on Edmodo. The explorer allows students to set the paremeters of a binomial distribution, n and p, and view the resulting probability distribution. After a few minutes of playing, I asked students what they noticed about these distributions.
Each group was equipped with a netbook, and some students chose to use their phones. A Desmos binomial distribution explorer I had pre-made was linked on Edmodo. The explorer allows students to set the paremeters of a binomial distribution, n and p, and view the resulting probability distribution. After a few minutes of playing, I asked students what they noticed about these distributions.
A lot of them look normal.
Yup. And now the hook has been cast. Which of these distributions “appear” normal, and under what conditions? In their teams, students adjusted the parameters and assessed the normality. In the expressions, the normal overlay provides a theoretical normal curve, based on the binomial mean and standard deviation, along with error dots. This provides more evidence as students debate normal-looking conditions.
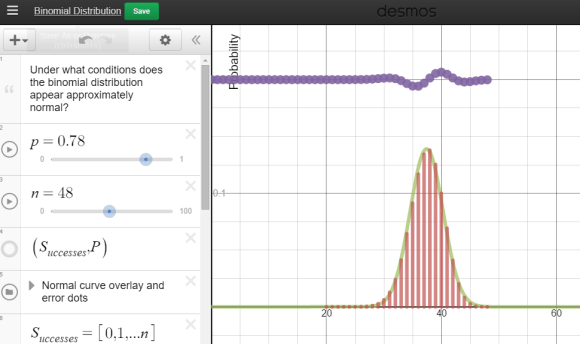
Each group was then asked to summarize their findings:
- Provide 2 settings (n and p) which provide firm normality.
- Provide 2 settings (n and p) which provide a clearly non-normal distribution.
- Optional: provide settings which have you “on the fence”
My student volunteer (I pay in Jolly Ranchers) recorded our “yes, it’s normal!” data, using a second Desmos parameter tracker. What do we see in these results?

Students quickly agreed that higher sample sizes were more likely to associate with a normal approximation. Now let’s add in some clearly non-normal data dots. After a few dots were contributed, I gave an additional challenge – provide parameters with a larger sample size which seem anti-normal. Hers’s what we saw:

The discussion became quite spirited: we want larger sample sizes, but extreme p’s are problematic – we need to consider sample size and probability of success together! Yes, we are there! The rules of thumb for a normal approximation to a binomial had been given in a flipped video lecture given earlier, but now the interplay between sample size and probability of success was clear:
And what happens when we overlay these two inequalities over our observations?

Awesomeness! And having our high sample sizes clearly outside of the solution region made this all the more effective.
Really looking forward to bringing this graph back when we discuss hypothesis testing for proportions.

8 replies on “When Binomial Distributions Appear Normal”
Given (by me) the probability of finding on “c” in a word, what is the probability of finding 3 ‘c’s in a row ??
Have you done any simulations of a sampling process, to check the reasonableness of the match in !!real!! situations ?
Your first questions eludes me – can you clarify?
Also, we do many simulations in my class.
Check the Desmos binomial distribution explorer and all will be revealed.
LOL, great catch. You had me scratccching my head there for a bit.
[…] asked to defend the np > 10 condition, was perfect timing for my classes. This year, I tried a new approach to help develop student understanding of the binomial distribution / sampling distribution […]
I’ve been playing around with this. If you engage the continuity correction to the binomial, using normalCDF to approximate binomial probabilities starts to work much better for even small sample sizes. Even with n = 6 and p = 0.5, the continuity-corrected normal CDFs are almost perfect! No worse than those from n = 40 and p = 0.25, for example. The skew seems to matter way more than the sample size in practice, when it comes to calculating. The sheer shape matters more when we’re talking about inference, of course.
Thanks for your comments David. At a recent local stats meeting, I chatted about normality in inference -and when it comes down to brass tacks, if you are worried about your sampling distribution “violating” normality, then your sample size is probably way to small to begin with.
[…] by Bob Lochel’s beautiful investigation on when binomial distributions appear normal, I started exploring, for myself, the other rule of thumb in statistical inference: the […]