The scenario I used for a fun lesson with my 9th graders this week comes from a talk by James Bush from Waynesburg College, which I attended at the US Conference on Teaching Statistics in May. James is a master of finding clips from TV and movies to use in his class to encourage discussion, and this clip from the Jimmy Fallon Late Show features a game called “Egg Russian Roulette”. I have embedded a clip here, but you can search for many times Jimmy played this game on his show.
For James’ college statistics courses, this clip is a helpful opener to the hypergeometric distribution, where we are interested in multiple successes from draws done without replacement. While this setting could eventually be presented to my AP Stats students, it lives a bit outside of the scope of what we do at the college level. But there are some strong entry points for discussion with my 9th graders, including probability trees, conditional probability, and simulation.
PLAYING THE GAME IN CLASS
Before showing the video, two volunteers were called to participate in a mystery game. The two student volunteers became a bit nervous over their decision when a carton of eggs was produced, eventually shown to be filled with plastic eggs (awesome idea by James!). My first chance to try this with volunteers on my own was at Twitter Math Camp in June, and lots of fun tweets followed.
Thanks to Richard Villanueva, who recorded many of the My Favorites from Twitter Math Camp, we have coverage of the ganeplay. Check out all of the videos of My Favorites from TMC15 on his YouTube Channel.
Next, I asked the class to think of questions they have about the game they saw, or in general about Egg Roulette. A good starting list developed:
- How likely is it that Tom Cruise would lose that quickly?
- Once Tom picks a raw egg, how likely is it that Jimmy is safe on his draw?
- Is it better to go first or second?
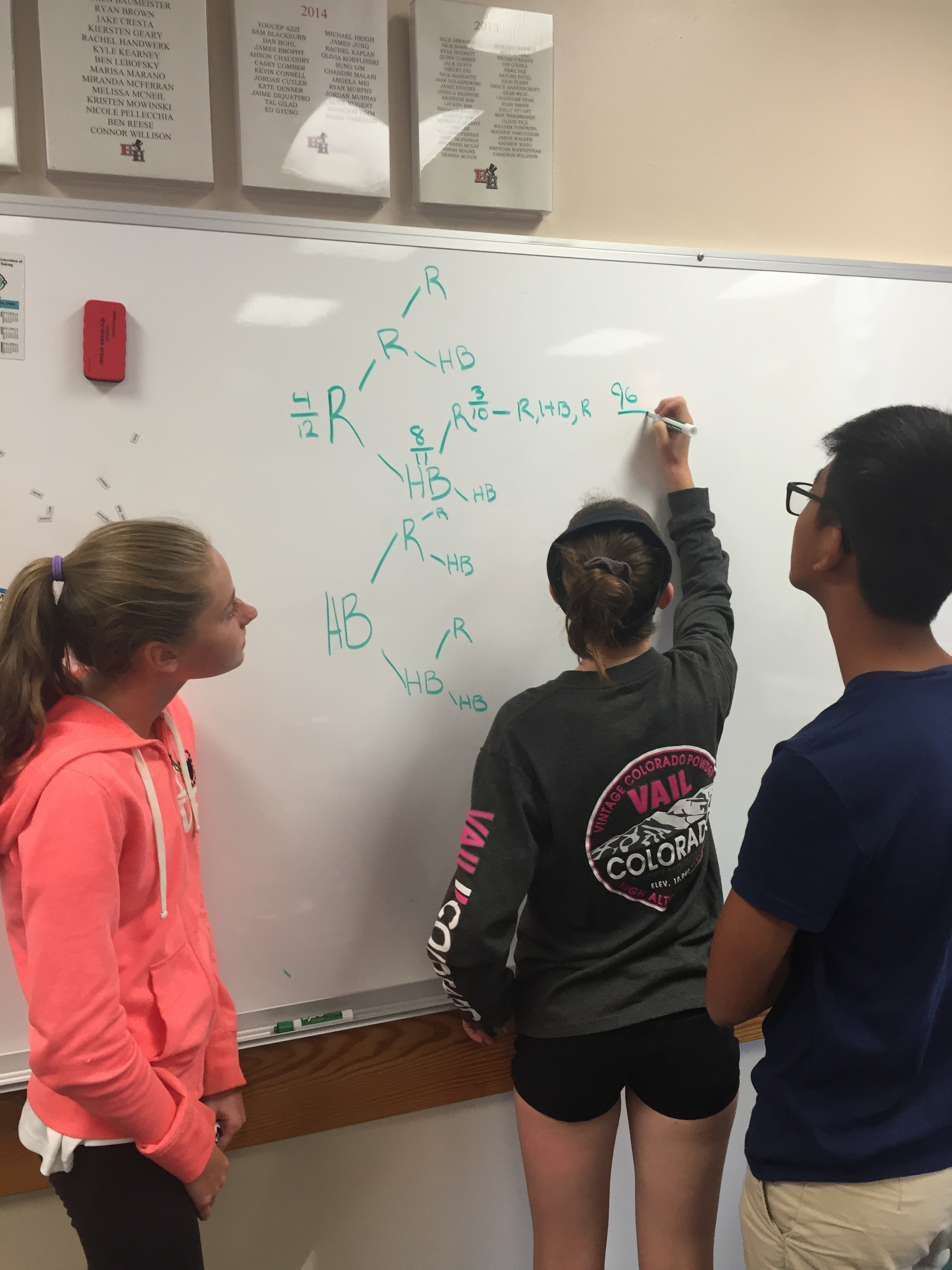 I then challenged my student groups to sketch out the first three rounds of egg roulette, and find the probability of Tom losing in 3 rounds. We had worked on trees the day before, and this game presented a good chance to apply what we had discussed earlier.
I then challenged my student groups to sketch out the first three rounds of egg roulette, and find the probability of Tom losing in 3 rounds. We had worked on trees the day before, and this game presented a good chance to apply what we had discussed earlier.
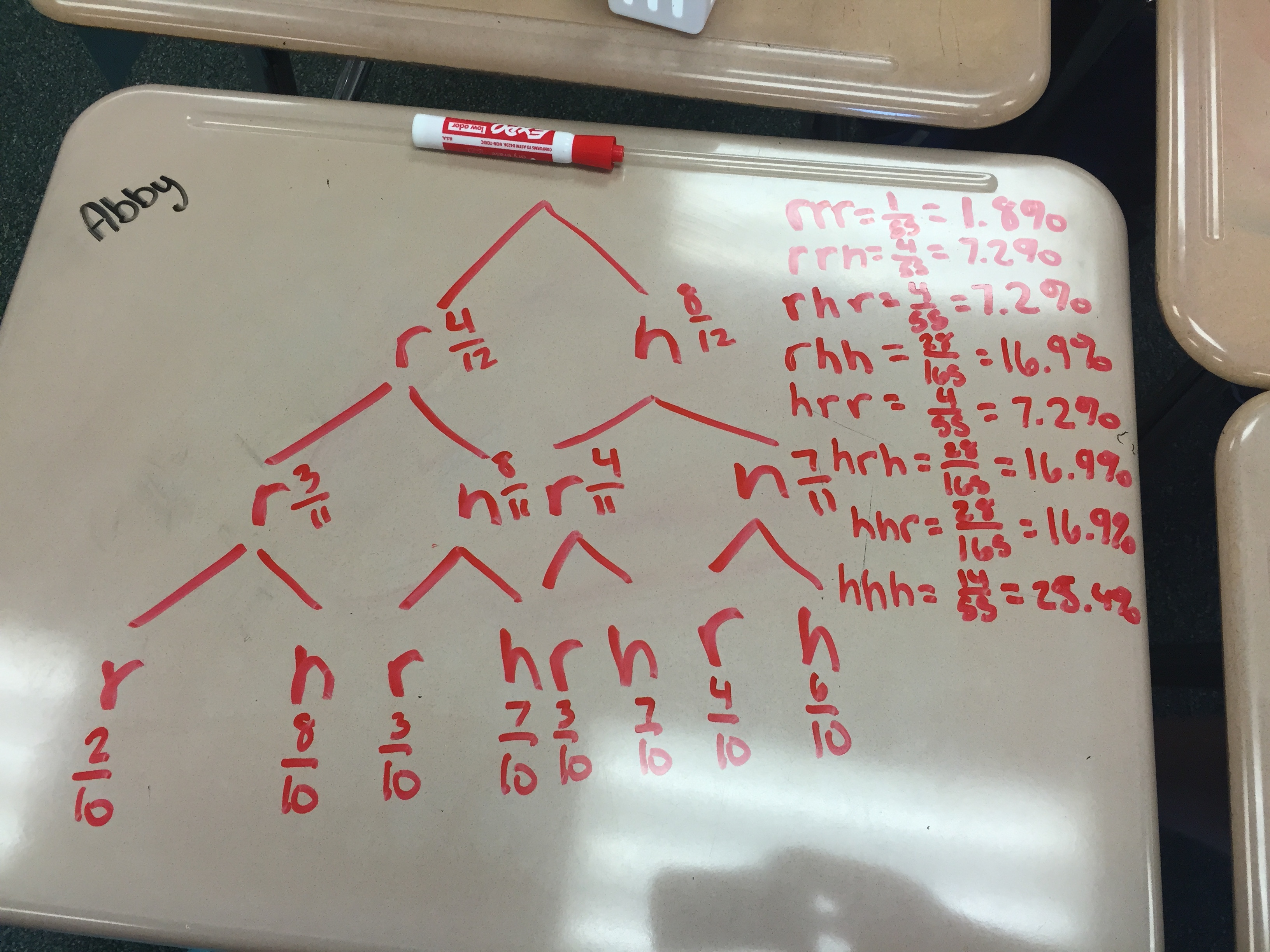
SIMULATION
After our analysis of the first three rounds, the conversation then moved to strategy: is it better to go first or second, or does it not matter? Our “gut reaction” poll revealed that “it doesn’t matter” was the most common response, with “go first” was in second place. The thought behind going first is that you could easily draw a hard-boiled egg, and thus put pressure on the other player.
To simulate the game, pairs of students were given one suit from a deck of cards. The ace was moved aside, leaving 12 cards (representing the 12 eggs). The 10, jack, queen and king then represent raw eggs. After shuffling the cards, students dealt cards into two piles, Tim and Jimmy. When a player was dealt two raw eggs, the game ends and the result recorded. We were quickly able simulate over 50 plays of Egg Roulette, and the class results were recorded.
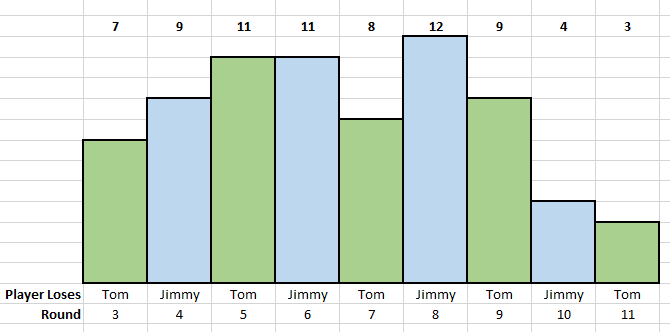
One student quickly identified, and then defended, that the game can NEVER go the full 12 rounds. Also, some students noted that the second player (here, Tom) has one extra opportunity to lose the game. A second straw poll revealed that student perceptions on the game had shifted – few thought it was a 50/50 game, and many saw that the first player held a disadvantage.
FOLLOW-UP
In teams, students are now challenged to explore a similar (yet shorter) Egg Roulette game, compute theoretical probabilities, conduct a simulation, and analyze the results. I’m looking forward to some interesting-looking trees. The document here shows guidelines for this activity, some assignment ideas, and a full tree for the first 3 rounds of Egg Roulette.