The book Making It Stick – the Science of Succesful Learning has caused me to consider how I approach practice and assessment in my math classroom. The section “Mix Up Your Practice”, in particular, provides ideas for considering why spaced practice, rather than massed practice, should be considered in all courses.
But it was an anecdote which began the chapter on spaced practice which led to an interesting experiment for stats class. The author presents a scenario where eight-year-olds practiced tossing bean bags at a bucket. One group practiced by tossing from 3 feet away; in the other group, tosses were made at two buckets located two feet and four feet away. Later, all students were tested on their ability to toss at a three-foot bucket. Surprisingly, “the kids who did best by far were those who’d practiced on two and four-foot buckets, but never on three foot buckets.”
Wow!
Let’s do it.
My colleague and I teach the same course, but on different floors of the building during different periods. Each class was given bean bags to toss, but with different practice targets to attempt to reach.
- In my class, lines were taped on the floor 10 and 20 feet from the toss line.
- For Mr. Kurek’s class, one target was placed 15 feet from the toss line.
 After every student had a chance to practice (and some juggling of beanbags was demonstrated by the goofy….), I picked up my tape lines, and placed a new, single line 15 feet from the toss line. Each student then took two tosses at the target, and distances were recorded (in cms).
After every student had a chance to practice (and some juggling of beanbags was demonstrated by the goofy….), I picked up my tape lines, and placed a new, single line 15 feet from the toss line. Each student then took two tosses at the target, and distances were recorded (in cms).
We then analyzed the data, and compared the two groups (the green lines are the means):
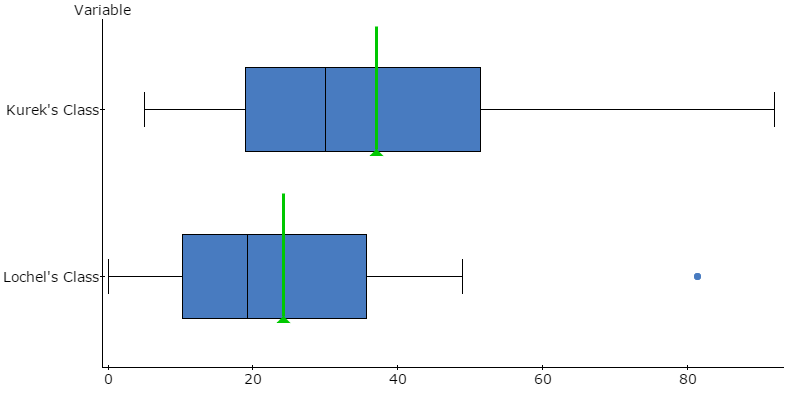
I love when a plan comes together! The students, who did not know they were part of a secret experiment, were surprised by the results – and this led to a fun class discussion of mixed practice. Here, the mixed practice group was associated with better performance on the tossing task. Totally a “wow” moment for the class, and a teachable moment on experimental design.




